
necko: the new netlib project
"it's wafer thin"
Author: Warren Harris & Rick Potts
Mozilla's current networking library is in a sorry state. Remnants of the old "mozilla classic" codebase pervade, and coupled with the fact that it was designed for a radically different non-threaded world where it was the primary scheduler for the browser (and performance is abysmal because this is no longer the case causing us to have to "poll" netlib to get any work done) -- we decided that it was about time to take the situation under control. [historical reference]
overview
The main function that the netlib kernel serves is to act as an efficient data pipe between multiple physical transports (ie. file system, network, etc.) and a standardized stream abstraction which protocol handlers consume.goals
There are three main design goals in the Necko kernel architecture - footprint, maintainability and performance.It is hoped that both the disk and memory footprint of Necko will be substantially smaller than the existing netlib. Existing dead code will be eliminated and the new modular design will allow "just enough" networking support to be loaded at any one time. This is in contrast to the existing netlib which is monolithic (500k for the core, not including mail/news protocols).
It is hoped that the new modular design and implementation of Necko will prove more maintainable than the existing code base. The biggest maintenance issues with the existing code base are its age (almost 5 years old) and the fact that the code was designed for a very different client architecture than Gecko. This new design is tailored toward a component-based client and is well suited to an open source environment where individuals can contribute new custom functionality to augment the core kernel implementation.
The implementation of Necko will include instrumentation mechanisms allowing a quantitive analysis of performance. Also, the pluggable nature of this architecture allows for custom (platform dependent) implementations to be substituted for the XP reference implementations provided within the netlib kernel. For example, a custom Win32 specific transport module could be written to maximize the performance of file I/O by utilizing platform specific APIs...
architecture
The netlib kernel can be divided into several functional pieces.- URLs
- Protocol handlers
- Protocol connections
- Transports
- Supporting services
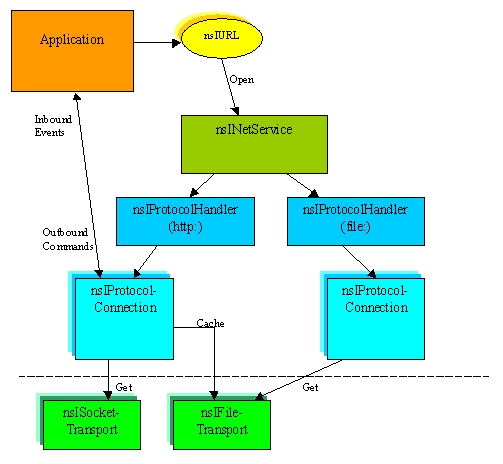
The application program initiates a network request by consructing a URL object and loading it. The network service (nsINetService) is a global singleton object obtained from the service manager that facilitates the construction and opening of URLs. The network service also provides functionality needed to support plug-in protocol implementations.
The network service extracts the scheme of the URL (the protocol name portion, e.g. "http:") and looks up a protocol handler to field the request. The protocol handler begins by constructing a URL object designed to work hand-in-hand with the protocol. The URL object can be an implementation supporting custom parsing code for that protocol's specified URL syntax, or a can be a "typical" URL implementation (one that only supports the accessors of nsIUrl, e.g. host, port, path, etc.) if that is all that is required by the protocol.
After building the URL object, the network service again contacts the protocol handler to load the URL. The protocol handler is then responsible for constructing a protocol connection object (nsIProtocolConnection) for the URL request. There is a one-to-one correspondence between protocol connections and URL load requests.
The protocol connection provides any protocol-specific accessors required by the protocol. For example, for the http protocol these include accessing the headers, making byte range requests, posting, etc. Any protocol-specific interfaces are obtained by calling QueryInterface on the protocol connection.
transports and threading
Within the protocol connection's implementation, transport objects (nsITransport) are used to make actual physical connections to the sources of data. The two most prominent examples of transports are socket transports for reading and writing to network sockets, and file transports for reading and writing to the file system. Others might include a JAR-file transport (for accessing data from JAR or ZIP files), or perhaps a timer transport (for getting periodic callbacks). Some protocols like http may reuse open transports for "keep alive" requests.Transports will run in their own logical thread, thereby allowing the application thread(s) to run asynchronously. When data comes in for a transport, the transport thread will marshal that data over to the application thread. The application thread will actually deal with parsing the incoming data (the protocol packet), and then pass application-specific data contained therein up to the application through a "protocol event sink." For the http protocol, the event sink will call the html parser as well as deliver progress and status notifications. For protocols like IMAP, the event sink will notify of events like new folder creation or incoming message arrival.
For socket transport requests, there will most likely be a single socket transport thread managing a pool of file descriptors for all outstanding socket requests. When data comes in for a socket, the socket transport thread will marshal that data over to the application thread. For file transport requests, there will be a default implementation of the file transport service that manages a pool of threads. Each incoming file transport request will be dispatched to the next available file transport thread. The number of file transport threads will be small (like 4), and is a tuning parameter. Again, when data comes in from a file, the file transport thread will marshal the data over to the application thread.
Applications received the marshaled data in one of two ways: synchronously or asynchronously. By requesting an input or output stream from a connection, applications can operate synchronously with respect to the protocol, blocking on read and write operations, respectively. This technique is used by protocol implementations that run in their own thread and can afford to block (and do nothing else) while waiting for data to come in from the transport. By making an asynchronous read or write request, applications can share their thread between parsing the protocol and performing other activities (such as running the UI). Using this technique, events will be delivered to the thread's event loop when data arrives, calling a stream listener (nsIStreamListener) that was supplied when the asynchronous request was made. Protocol-specific accesses can be done is a similar way, either synchronously or asynchronously. These will manifest themselves as "outbound commands" on the connection, or as asynchronous requests and "inbound events" on the application's event sink respectively (see the diagram, above).
Isolating the transport from the protocol handlers provides a single point where platform specific optimizations can be performed on a per transport basis. For example, a custom Win32 implementation of the file transport using overlapped file I/O could be written without disturbing the rest of the netlib implementation. Each transport is responsible for efficiently scheduling its transport requests. In general, a transport implementation will run in its own thread to avoid polling. Transport implementations are responsible for timing out requests which have not been fulfilled within a specific amount of time. The transport layer also provides a central point to perform resource throttling (ie. limiting the number of simultaneous connections) and connection pooling such as reusing open connections for subsequent requests.
getting involved
Here's a brief list of some initial ways you could get involved in the Necko project:- provide general feedback on our design and implementation
- build stand-alone tests for the file and socket transport layers
- build a general stand-alone test harness for testing the various protocols
- write a wrapper to allow the Microsoft inet.dll to work under the Necko APIs
- write a wrapper to allow whatever inet-equivalent networking code that may exist on the Mac to work under the Necko APIs
- measure performance and provide optimizations
- implement platform-specific async-I/O to replace thread-pool based file transport
- implement miscellaneous protocols, e.g. WAIS, Gopher (after protocol architecture is further along)
- implement a telnet protocol and terminal window that fits into the general XUL-based browser UI (extra credit)
- help us compile a document describing networking "gotchas" that we need to keep in mind as we proceed
- you tell us what you'd like to do...
- Rick Potts -- core architecture, socket transport
- Gagan Saksena -- http protocol, cache architecture
- Hubert Shaw -- security issues
- Gordon Sheridan -- async dns implementation
- Judson Valeski -- ftp protocol
- Warren Harris -- core architecture, file transort, http protocol
Tour our lovely source tree at Repository Directory /cvsroot/mozilla/netwerk.
Or visit our sponsor and raison d'être: www.necco.com.