Replacer Tool Specification
Newsgroup: mozilla.dev.tech.cryptoTechnical contact: Bob Relyea
Yell at the manager: Bob Lord
(Last updated: 6/30/98)
Contents:- Overview
- Command Line Interface
- Single Source Testing
- Replacer Specfile
- Java Mode
- Rules
- Template File Specifications
- Special Meta-Variables
- Examples
Overview of replacer (Replacer Test Tool)
Replacer is a general-purpose program to produce a large number of programs that are nearly identical, differing by only a few variables. This program is ideal for creating regression test suites on APIs or programs that have large numbers of variables.This diagram outlines the overall process that a test suite should go through with replacer. The replacer takes in three input files: a source code template file (could be any language), a template makefile, and a replacer specfile. It outputs many source code files, a makefile and a regress specfile. The source code files are then built with the makefile, and the executables are run through regress to generate the regress report. This is html readable.
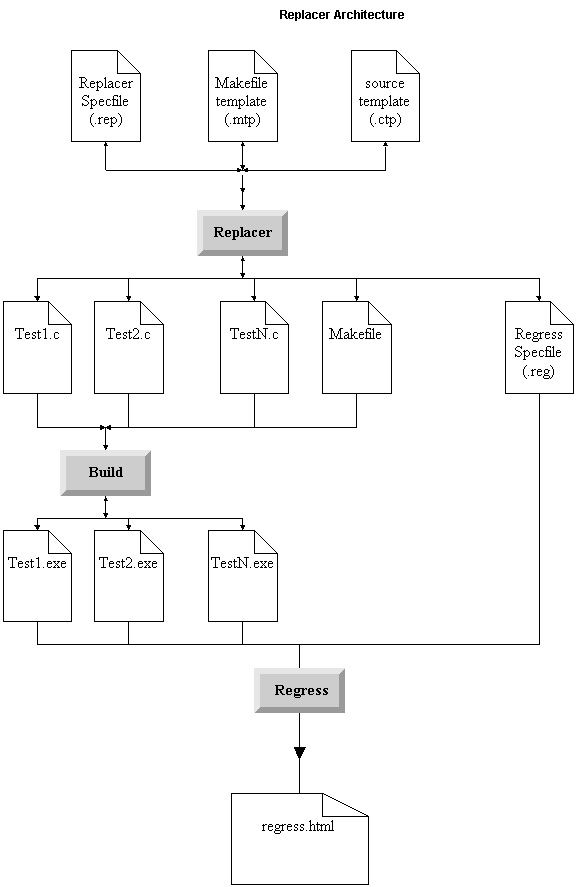
This specification is still currently under review and open to change.
Single source testing method
In order to have ability to use single source and single executable to test wide range of cases some modifications are required to current versions of replacer and regress. Simple way to achieve this flexibility is to inject all tested data in a form of following structures. data_type variable[] = {
data-1,
... ,
data-n
}
Here, each data-<x> in the table represent one of many possible
combinations of a specific variable.
These tables can be constructed and injected by replacer from the data
collected from its template file. This way we can use single executable
to test all required cases.
Regress has to run each test with test ID as a parameter, the test executable will extract the appropriate set of combinations based on the TestID. Test ID encoding and decoding can be done many ways. A simply method is to use multiplication and division. Let do simple example to illustrate this method. Lets assume that we are testing n variables. Each of them are assigned a particular value by replacer's combo generator: M1, M2, M3, ... ,Mn. These values M1 .. Mn are stored in the injected data tables with indices of V1, V2,..., Vn. respectively. Then testId is simply generated from a mathematical combination of these index values and the combination values as follows:
testId = ( ((Vn*Mn-1 + Vn-1)*Mn-2 + Vn-2)*Mn-3 + )*M1 + V1;
The executable at runtime can figure out which set of combinations to extract based on calculations using testID (as follows):
V1 = testId % M1;
V2 = (testId / M1) % M2;
V3 = ((testId / M1) / M2) % M3;
... ;
Vn = (
((testId / M1) / M2)
) % Mn;
Since testID is passed as the first argument to the executable, a single
executable can test all test combinations by just executing it again and
again but each time
with a different testID. This also means, that
replacer has to lookup $[VARIABLEn] with corresponding variable-n-data_table[(
((testId/M1)/M2)
)%Mn]
instead of specific data combinations as before.
Regress template file produced by replacer has to have test IDs in each test section. However regress specfile will no longer require a program field in each section, but rather just one field program in the general header. (see replacer specfile)
see also: regress and replacer modifications: single source mode
Command line interface
replacer specfile=filename [singleSource] [debug] [lang=java|c] [jvm=<path to Java Interpreter>][classpath=<java CLASSPATH setting>]
Replacer Return Codes
| Error Codes | Description |
| 0 | No error |
| 1 | Did not include specfile= directive on command line |
| 2 | Specfile is malformed or does not exist |
| 3 | No [General] header in specfile |
| 4 | No cTemplate= in [General] section. |
| 5 | No makeTemplate= in [General] section. |
| 6 | No path= in [General] section. |
| 7 | No regressSpecfile= in [General] section. |
| 8 | No regressOutput= in [General] section. |
| 9 | No mut= in [General] section. |
| 10 | No mutversion= in [General] section. |
The following is a specification of the replacer tools Test Case Specification file. The current convention is for these specfiles to have an extension .rep (this is not enforced by any means, but this is purely for readability's sake). You can see the list of current filename conventions here. Please look at the conventions if you don't know them by heart for other people's sake...
[Note: this specification may be difficult to understand so be sure to check out the example that follows this carefully]:
| Specification File Element | Description of Element |
| [General] | Starts the General information block that describes basic settings for the suite of tests. This must be the first block. |
| mut = <string> | Defines the Module under test. (what module you are using this specfile to test -- pretty much a "title" field) |
| mutversion = <string of numbers> | Defines the version of the module under test. |
| cTemplate=<template filename> | Defines a file that is read in as a C Template file. See definition of Template file below. |
| makeTemplate=<template filename> | Defines a file that is read in as a Makefile Template file. See definition of Template file below. This template file is different in that $[CSOURCES] is the only variable, and all the .c files that are generated by the replacer will be stored there. |
| path=<path> | Defines the directory that all the generated C files, Makefile, and
regressSpecfile are put. If the file is prefixed by /, the path
is absolute, otherwise the filename is relative to the present working
directory. The program will generate that directory if it doesn't exist
already.
The path will be parsed such that on Windows machines, the slashes will be replaced with backslashes. The same goes vice versa for Unix machines. This header is optional. The path will be default to "." if it is not set. |
| testPrefix=<string> | Defines the first few characters of the output
code. All the tests will be these strings concatenated:
<prefix><testnumber><suffix> Ex. prefix=test
The tests will be:
Note: this header is optional. If the testPrefix is not defined, the replacer will assume a "t" as the prefix. All generated output source files will be prefixed with path/ |
| testSuffix=<string> | Defines the last few characters of the output
code. See definition above. The executables are assumed to have <testPrifix><testNumber>
and the source are assumed to be <testPrefix><testNumber><testSuffix>
Note: this header is optional. If the testSuffix is not defined, the replacer will assume a ".c" as the suffix. |
| timeout=<number> | Defines the maximum time in seconds any test
can run. This is for all tests.
This header is optional. If the timeout is not defined, the timeout will be the same value as the regress default timeout (10 seconds). |
| regressSpecfile=<filename> | Defines the filename of the generated regress specfile. The specfile will be prefixed with path/.If the file already exists, it will be overwritten. |
| regressOutput=<filename> | Defines the htmlout field inside the regress specfile header. This is the html file that gets generated by the regress tool to report the test results. If it already exists, it will be overwritten. |
| reporterOutput=<filename> | Defines the reporterSpec= field inside the generated regress specfile header. This is the specfile that gets generated by the regress tool and is input to the reporter. |
| randomSeed=<number> | This specifies a seed for the random part of the test generation (so you can have the same tests generated every time). This header is optional. If you don't specify a seed, an automatic seed of 0 is set. |
| globalArgument=<string> | This defines the globalArgument field inside the regress specfile header. |
| singleSource = <TRUE|FALSE> | Defined to use single source testing method. If singleSource is specified, there is no need to set makeTemplate. Make file template wont be modified. |
| firstExitCode = <number> | This defines first exit code number used by replacer to substitute meta-variable $[EXIT-CODE]. This field is copied to the resulting regress specfile (General section) as firstErrorCode=<number> |
| firstKnownFailure = <number> | This defines first code number for known failure and is used by replacer to substitute meta-variable $[KNOWN-FAILURE]. Assuming that number of known failures is small, firstExitCode is treated as the upper limit for known failures, which means, that firstKnownFailure should be smaller than firstExitCode. |
| maxOfCombinations = <number> | This defines maximum number of combinations (default 500,000). |
| JAVA MODE SPECIFIC FIELDS | |
| language=[c|java] | This tells replacer whether the source template is C or Java. Setting language=java places replacer in JAVA_MODE which exhibits behavior slightly different from the default C_MODE, see Replacer in Java Mode in the next section for more details |
| mainClassName=<name of Class containing main()> | Absolutely required in Java mode. This field is required by replacer to qualify variable names correctly in single Source mode. Also, replacer needs to know the class name in order to generate the correct regress spec file so that regress knows the name of the class file its running. This field is directly copied to the generated regress specfile. |
| jvm=<full path of the Java interpreter> | Required if the produced regress specfile is to know which Java interpreter to use to run each test. By default, jvm=java. As a warning however, most systems will not be able to find 'java' unless you specify the jdk in your $path (or $PATH). This field is directly copied to the auto-generated regress specfile. |
| packageName=<name of the package, the class is enclosed in> | Required if you have a package declaration in your code. This field is directory copied to the generated regress specfile, so that regress can piece together what executable it is suppose to run. (May be left out if there are no package declarations in the source template, or if you don't want replacer to create a directory tree for you). |
| classpath=<your CLASSPATH setting> | This field is copied to the generated regress specfile, so that regress knows what to set the CLASSPATH to when running your testsuites. If classpath is specified at the command line, it will override the classpath set in the specfile. |
| When in Single Source Mode [optional]
makefile=<makefile template name> makefileOutput=<outputted makefile's name> |
In JAVA_MODE and single source mode, if a makefile and makefileOutput
is specified, then replacer will substitute the metavariable $[CSOURCES]
with
the name of the source file created and create a makefile based on the makefile template. If these fields are not specified, replacer will behave just as it does in C_MODE (that is create no makefiles). |
| createDirs=[TRUE|FALSE] | If set to true, replacer will create the proper directory tree in which to house your Java source code. For example had you specified packageName=com.Netscape , replacer will create the directory <path>/com/Netscape/ and place the source code in that directory. By default, replacer will write the test suite source code in the current directory or where <path> was specified. |
| Specfile Element | Description |
| [Some-Variable-Name] | This defines a variable that will be varied under all the combinations possible. The following elements are under this header. |
| IMPORTANCE=HIGH
IMPORTANCE=LOW |
This determines the importance of varying this variable. If this header does not exist, this is automatically default to "importance=high". If "importance=high", the combination generator will make sure that every combination of this variable gets varied for every combination of the other high importance variable. Otherwise, for every cycle a random value will be chosen for the output program. This header MUST be before the DEPENDENCY header and any other header. |
| DEPENDENCY=$[Variable-Name]==Value ||
$[Variable-Name-2] ==Value-2 || $[Variable-Name-3] !=Value-3 && $[Variable-Name-2] == $[VariableName-4] || ... |
This defines a dependancy in the template file. If this variable is
of "high importance," it is highly advisable that it not depend on "low
importance" variables. The replacer may not function reliably in that case.
Future versions of replacer will check this.
Whenever there is a DEPENDENCY header, the variable will be run through and be varied if and only if the expression holds. All the variables evaluated in the dependency must be declared before the current variable. Also, the expression must be in sum of products form (no parentheses). For example the following statement:
The boolean parser first parses and separates the expression on the basis of ||s. Then for each sub expression the boolean parser splits on the basis of &&s. After the splitting by ||s and &&s, the expression should be consist entirely of relations. i.e. comparisons using ==(equals), != equals, << less than, >= greater than or equal to, >> greater than, and <= less than or equal to. The evaluator will perform the << and >> and == and != functions by substituting the variables with the values and then performing a strcmp between them, so alphabetical comparison and numerical comparison will be supported. This boolean evaluator will not support parentheses. However in the future, the evaluator can easily be taken out and replaced by a better one, if demand is there. The evaluator is located in ns/ttools/lib/src/ttools.c |
| TYPE =<data_type> | Each tested variable has to have specified type in its information block for the single source testing method. Types suppose to be defined after IMPORTANCE and DEPENDENCY but before NULL_VALUE and VALUES. |
| NULL_VALUE =<value> | This defines a null value for single source dependencies. NULL_VALUE suppose to be defined after TYPE and before VALUES only if DEPENDENCY is defined and only in a single source mode. |
| <comment>=<value1>
<comment>=<value2> <comment>=<value3> |
This tells us what values the variable should be varied as. The comment is used to help comment the regress specfile so you can tell which test is being run. All the comments of all the variables and values used during the test will be concatenated and put in as the name of the test. These must be AFTER the IMPORTANCE and DEPENDENCY headers. |
Rules Header
| Specification File Element | Explanation |
| [rule-<label>] | A rule definition section must have a header that contains
"rule-", the number that follows is up to the user. Replacer assigns rule priority in the order which those rules appear, and NOT based on the number associated with the rule. |
| bug=<bug number> | bug should be defined if this rule is designed to filter out a known bug. The bug number is extracted by replacer and copied to the bug field of the [Test-n] block of the regress specfile, which corresponds to the combination that satisfied this rule. |
| ignore=[TRUE|FALSE] | This is an optional field. If the bug field is not specified under this rule, ignore is set by default to FALSE. If ignore is set to TRUE, then replacer will not run any tests that satisfy this test. If neither ignore nor bug is specified, then this rule will not have any effect on the tests. |
| <comment-1>=<boolean expression defining a (sub)rule>
<comment-2>=<boolean expression defining a (sub)rule> <comment-3>=<boolean expression defining a (sub)rule> ... <comment-n>=<boolean expression defining a (sub)rule> |
Comment can be anything except 'bug', or 'ignore' or any phrase
with a '=' in it. The comment is just there for the user's
own reference purposes Replacer simply ignores it.
The boolean expression that follows specifies a sub-condition in which a test combination must satisfy inorder to satisfy the entire rule. You may define more than one comment=<bool exp> in a rule block.
However, when evaluating the rule, replacer simply treats multiple subrules
as
Each sub-rule boolean expression must be in sum of products form same
as that for DEPENDENCY statements. The implementation of the
boolean evaluation uses the TTOOL's library functions. Hence
the supported tokens will be:
Variables in these boolean expressions should be wrapped:
An example rule definition would be: [rule-yourMoneyOrYourLife]
|
Replacer In Java Mode
Overview:
In order to make replacer compatible with Java source files, changes were made to:
- Syntax of data tables and variables injected or replaced (in Single Source Mode).
- Replacer Specfile Fields
- File Naming and source file storage location
Syntactic Changes
Array Initializer Changes in Single File Mode:
In single source mode, replacer injects data
tables containing all the values a variable may take on into the generated
source code. Array initializers in C/C++ vs Java vary
in the placement of '[ ]' in the declarations.
The fix simply injects
"dataType[ ] variableName
= { data-1...data-n }"
when under Java mode but
"dataType variableName[
] = { data-1....data-n }"
when in C mode.
Variable Name Qualification:
In order to have the above mentioned data tables
be visible to the entire class as well as possibly other classes in the
package, the data tables/arrays are declared as "public static".
During combination substitution replacer replaces $[VARIABLEn]
in the source template with <mainClassName>.<variableName>[(...((mainClassName.testId/M1)/M2)...)%Mn],
which is the fully qualified name for that table entry.
The variable testId is also qualified by the mainClassName and
like the data tables is declared as a public static field in the main class.
TestId retrieval:
While operating under Single Source mode, testId
is taken as the first argument to the test executable.
Under C/C++ mode, "testId = atoi( argv[1])" would do to
retrieve and initialize the testId from the command line args.
Whereas under Java mode testId is initialized by "<mainClassName>.testId
= Integer.parseInt(argv[0]);".
Replacer Specfile Changes: ( all field addition should go under the [General] header.)
In order to differentiate Java mode from C/C++
mode, an additional field "language" must be added to the Replacer
specfile. Currently, setting "language=java" (all
lower case) will place the replacer in JAVA_MODE.
Similarly, the user can set to replacer to Java mode by specifying at the
command line the extra option "lang=java". (Note
in the future the substring 'java' can be replaced by 'javaScript' or 'Lisp'
or other languages we wish replacer to support.)
Specifying lang=java at command line will override
the language setting set in the replacer spec file.
In JAVA_MODE, the field "mainClassName=" must appear in the [General] section. Replacer uses the value given for mainClassName to qualify all the variable names in Single source mode (see above section on variable name qualification). If mainClassName is not specified, Replacer will throw the error REPLACER_NOCLASSNAME on exit.
The user should add the field "jvm=" in the [General] section. The value should be the full path of the Java Interpreter the user wishes to use to run their tests with (e.g. jvm=/tools/ns/bin/java). If the jvm field is missing, replacer will used 'java' as a default. However on most machines, 'java' will not work since the environment in which the test programs runs may not have the java interpreter in its $path.
The classpath attribute is also important if the user wishes to tell regress to use a CLASSPATH other than the one specified in their environment. This attribute can be set in the [General] section of the replacer specfile or at the command line. In either case, the name and value pair is copied directly to the generated regress specfile. (The command line setting overrides any settings of classpath in the specfile.)
Additionally in JAVA_MODE, if the source file contains a package declaration, the user should specify the name of the package under the heading "packageName=<package name>". For example, if "package foo.bar;" appears in the template source code, then user needs to specify packageName=foo.bar in the replacer specfile. This field is optional, and only required if the user has a package declaration. Note: replacer will construct the appropriate directory structures to store the resulting .java test source files based on the value set under packageName.
Output Regress specfile Changes:
While under JAVA_MODE, (either Single Source or Multiple Source mode) replacer generates a regress specfile which has the following fields added to the [General] section:
language=JAVA
jvm=<your jvm
[default='java']>
mainClassName=<your
main class name>
classpath=<your
CLASSPATH setting>
packageName=<your
package name>
The last field packageName is optionally added depending on whether or not the user specified a packageName in the original replacer specfile. (The same also applies for the classpath field.) These 5 fields are necessary in providing regress with the pertinent information to find and run the tests in JAVA_MODE.
Under Single Source mode, replacer in C_MODE would set the program
field (under the [General] header) to
[General]
...
program=<executable>
....
but under JAVA_MODE, the program field is no longer
necessary. Regress will simply construct the program to run by combining
jvm, mainClassName and packageName fields in the following format:
<jvm> <packageName>.<mainClassName> [args]
Under Multiple Source mode, the replacer in C_MODE would set each program
field under each [Test-n] header as:
[Test-n]
.....
program=<executable>
.....
Under JAVA_MODE, these program fields are set
to
[Test-n]
....
program=<test directory
name>
....
"test directory name" is the name of the directory
generated by replacer when it is producing source code for [Test-n].
The idea is that for each test case, we create a separate directory for
that test case. The name of that directory will be based
on the test source code filename minus its suffix. (e.g. t1.java
is place under the directory t1) These separate
directories are required, because when javac compiles each .java
source file, .class files of the same name will be produced.
Putting the source in separate directories prevents filename clobbering.
Furthermore, if the user specifies a packageName in the replacer specfile and sets createDirs=TRUE, replacer will create a directory tree based on that packageName. For example if the user specified in the replacer specfile [General] section: packageName=foo.bar then replacer will create starting from the testing directory the directory foo/bar/. The produced source code file will reside at the tip of that directory tree ( Hence if t0.java is the file, it's full path now will be t0/foo/bar/t0.java ). If this feature is not desired, one can simply specify createDirs=FALSE (or not specify the createDirs field at all). In which case, the generated source file will be placed in user's current directory or in the directory specified by the user's path= attribute.
If the meta-variable $[CSOURCES] is specified in your makefile template, replacer will substitute that meta variable with the names (with path) of all the test source files. The $[CSOURCES] metavariable is the place holder (put inside the user's makefile template) that tells replacer where in the makefile template to insert the list of all the test source filenames. The behavior of this replacement is basically the same in JAVA vs C MODE in multiple source mode. However, in JAVA_MODE, the inserted filenames has in addition, the entire path of the file. For example, if replacer generated source code and placed them in t0/foo/bar/t0.java, the entire path, and not just t0.java will appear the the final Makefile.
While in JAVA_MODE and Single Source mode, the user may still specify an makefile template name "makefile=<makefile name>" and a makefile output filename "makefileOutput=<makefile output name>" in the specfile. In this case replacer will create a makefile that has $[CSOURCES] replaced with the name (with path) of the single file generated. This may be a convenient feature for Java Classes with very long package names.
See also Rules Header (Under Replacer Specfile)
When replacer generates hundreds and sometimes thousands of test sources, running all of them can be time consuming and resource intensive. In many cases, some subset of tests are known to fail or are associated with known bugs. And in other cases certain combinations of inputs simply are not necessary or will not occur. (Processing these combinations are simply a waste of time) For example, if a module written is guaranteed to only get input of numbers less than N, then those tests with inputs greater than N should be thrown out or simply ignored.
Rules defined in a replacer specfile constitute a mechanism by which to filter out certain test input combinations. Based these user defined 'filtering rules', Replacer will identify which test combinations are known bugs (and mark them in the regress specfile), and which ones should be simply ignored.
To define a rule simply add a section in your specfile called [rules-<label>]. Even though the label associated with the rule is completely ignored by the parser, it is good to have it as a way of distinguishing different rules. The following are some examples of rule definition:
# this rule tells replacer to mark ignored for all combinations
# that have INPUT > 5 and INPUT < 0
[rule-N]
gets rid of inputs greater than 5= $[INPUT] >> 5
and get rid of inputs less than 0=$[INPUT] << 0
ignore=TRUE
# this rule tell replacer to mark all sources that have combinations
# that fit the following rule with the bugNumber specified in the bug
field.
[rule-Y2Kbug]
mark y2k bug=$[YEAR] >> 1999 && $[DAY] >> 31 && $[MONTH]
>> 12
bug=2001
The order in which these rules are defined in the replacer specfile define the order in which they are evaluated (hence their precedence). For example consider the case that both [rule-N] and [rule-Y2Kbug] satisfy the input combination X1, X2, X3, X4. However since rule-Y2Kbug came after rule-N in the file, what ever action taken for rule-1 is taken (in which case the combinations are ignored).
Also, because rules are parsed differently from variables, rule definitions can go any where in the specfile after the [General] block.
Template file specification
Template files are simple ascii text files that have a few variables in them. The variables are denoted as $[variable-name]. These variables will be replaced by the values in the replacer specfile.Another feature of the specfile is that you can add #replacer-if, #replacer-else, #replacer-endif statements. Here are examples:
NOTE: there was a slight modification here at July 16th, 1997, so read this extra carefully if you used a alpha version of replacer:
#replacer-if $[variable-name]==value
.. some code ..
#replacer-else
.. some other code..
#replacer-endif
Or you can do
#replacer-if $[variable-name]!=$[variable-name2]
&& $[variable-name3] >> some-value || $[variable-name4] == some-value
.. some code ..
#replacer-else
.. some other code..
#replacer-endif
The replacer will evaluate the expression and execute the code segments accordingly.
Nesting is supported for up to 50 nested ifs (if you want more for some insane reason, you can modify a define in the source code). The #replacer-<command> must be at the beginning of the line.
Some other features include the #replacer-define and #replacer-undef. These are exactly the same as the cpp #define, except for three things. The first thing is you must specify a value to the define. The other thing is that something can be redefined and there will be no error. The last thing is that you are allowed a maximum number of 64 extra variables defined. (this can also be easily changed in source code). See example:
#replacer-define THREE 3
if ($[THREE] == 3)
printf("This is how you
use the #replacer-define, %d\n", $[THREE]);
#replacer-if THREE==4
printf("Of course 3 does not equal 4, you fool.\n");
#replacer-endif
#replacer-undef THREE
which will output:
This is how you use the #replacer-define, 3
Of course 3 does not equal 4, you fool.
However, use of #replacer-undef is strongly discouraged. Currently there is a chance for a small memory leak to occur when playing around with #replacer-undefs. It is better just to re- #replacer-define something to something else rather than #replacer-undefing something.
The #replacer-<command> is not working with single source testing method, because tested values are set at the run time.
Special Meta-Variables
| Meta-Variable | Explanation |
| $[LINE-NUMBER] | For all runs of replacer, a special variable called $[LINE-NUMBER] will be always defined. This will correspond to the line number in your generated source file, which may be helpful for debugging. |
| $[TEMPLATE-LINE-NUMBER] | Corresponds to the line number in your source template file that generated the code |
| $[EXIT-CODE] | Meta-variable $[EXIT-CODE] is dedicated to manage test exit codes. Replacer assigns consecutive numbers to every occurrence of $[EXIT-CODE] in a C-template starting from 1 or the number define by firstExitCode in general section of the replacer specfile. |
| $[KNOWN-FAILURE] | Meta-variable $[KNOWN-FAILURE] is dedicated to manage test exit codes designated for known failures. Replacer assigns consecutive numbers to every occurrence of $[ KNOWN-FAILURE] in a source template starting from the number define by firstKnownFailure in general section of the replacer specfile. Codes for known failures are limited from the top by firstExitCode defined also in general section of the replacer specfile. |
| Meta-Variable | Explanation |
| $[DATA-TO-TEST] | Tells replacer where to inject all data used by test. All types required by this data, have to define above it. |
| $[SET-TEST-ID] | placed at the beginning of the test main function to set testID from command line argv[] |
| $[TEST-ID] | Variable containing test ID value |
Where to put $[DATA-TO-SET]
and $[SET-TEST-ID]
C Mode Example:
$[DATA-TO-SET] /* replaced by injected data arrays */Java Mode Example:int main (char** argv, int argc) {
$[SET-TEST-ID] /* replaced by testId = atoi(argv[0]) */
...Code....}
$[DATA-TO-SET] tells replacer where to inject the public static data tables (declarations) and testId declaration when in Single Source mode. $[SET-TEST-ID] tells the replacer where to place "<mainClassName>.testId = parseInt(argv[1])" inside main(). The example below shows the proper locations for $[DATA-TO-SET], and $[SET-TEST-ID]:
class Example {$[DATA-TO-SET]
public static void main(String argv[]) {
$[SET-TEST-ID]
...Code...}
}
Examples
Example 1
This is a sample specfile snippet and the combinations that are output:[food]
IMPORTANCE=HIGH
Pizza=p
Chicken=c
Dogfood=d
[toppings]
IMPORTANCE=HIGH
DEPENDENCY=food == p
pepporoni=p
mushrooms=m
onions=o
oregeno=xx
This would result in 6 .c files. And as templates are evaluated, they are evaluated with the following variable substitutions:
food=p toppings=p
food=p toppings=m
food=p toppings=o
food=p toppings=xx
food=c
food=d
The following is a different example of the replacer tool in action. Note: This test was just updated as of July 25 5:11 pm.
A brief description of this sample is it tries to simulate a chain of objects being varied. This chain has a maximum length of 3. So all three objects in the chain are varied (upper-case or lower case). However, when you have a chain of length 2, you don't want to vary the 3rd object in the chain (you don't want to create spurious .c files that are duplicates of each other). So you put in a dependency header.
Input to replacer:
testspec.rep (replacer Specfile)
testemp.ctp (C template file)
testmake.mtp (Makefile template file)
Output (all in workarea/ )
t0.c t1.c t2.c
t3.c t4.c t5.c
t6.c
t7.c t8.c t9.c
t10.c
t11.c t12.c t13.c
t14.c
t15.c t16.c t17.c
t18.c
t19.c t20.c t21.c
t22.c
t23.c t24.c t25.c
t26.c
t27.c t28.c t29.c
t30.c
t31.c t32.c t33.c
t34.c
t35.c t36.c t37.c
t38.c
t39.c t40.c t41.c
This example demonstrates the Java support features and rule definitions for single Source mode.
The Java Template file looks like the following:
package TestTools.Replacer;
class Test {
/* below lies the injected datatables */$[DATA-TO-TEST]
/* following array is part of
template */public static int myMatrix[][] = {
{ 0, 0, 0, 0, 0 },
{ 1, 0, 0, 0, 0 },
{ 1, 2, 0, 0, 0 },
{ 1, 2, 3, 0, 0 },
{ 51, 2, 3, 4, 0 } };
public static void main(String argv[]) {} // end of Test
$[SET-TEST-ID];
System.out.println("User is " + $[STRING]);
System.out.print("is now accessing Matrix element Row: ");
System.out.print($[ROW]);
System.out.print(" Col: ");
System.out.println($[COL]);
int exitValue = myMatrix[ $[ROW] ][ $[COL] ];
System.out.println("The exit value is: " + exitValue);
System.exit( exitValue );} // end of main
Basically this program goes through all the possible row and column
index combinations, and exit with a
return code specified in myMatrix[ROW][COL].
If this template is ran will out 'rule' restrictions, all tests that have
row and column coordinates in the lower left
triangle (of the matrix) will FAIL. (Because they all have non-zero
exit codes) However if the following rules were applied.
[rule-2]
ignore lower triangle=$[COL] << $[ROW]
ignore=TRUE
[rule-1]
password=$[STRING]=="Robert Fulghum"
bug=1234
Note: The rule label is arbitrary here. Rule-2 will be evaluated before rule-1 simply because it came first.
Because of rule-2 all the tests with ROW & COL combinations that
are in the lower left triangle of myMatrix will be ignored.
After which rule-1 is applied to those ROW & COL combos where rule-2
did not apply. The results after running regress are
here in javatest.html
Because Replacer is in single source mode, the following single t.java source file is produced:
package TestTools.Replacer;
class Test {
/* below lies the injected datatables */
public static int testId = 0;public static int[] ROW = {
0,
1,
2,
3,
4
};public static int[] COL = {
0,
1,
2,
3,
4
};
public static String[] STRING = {/* following array is part of
"Dave Barry",
"Robert Fulghum"
};
template */
public static int myMatrix[][] = {
{ 0, 0, 0, 0, 0 },
{ 1, 0, 0, 0, 0 },
{ 1, 2, 0, 0, 0 },
{ 1, 2, 3, 0, 0 },
{ 51, 2, 3, 4, 0 } };
public static void main(String argv[]) {} //end of Test
Test.testId = Integer.parseInt(argv[0]);;
System.out.println("User is " + Test.STRING[Test.testId/5/5%2]);
System.out.print("is now accessing Matrix element Row: ");
System.out.print(Test.ROW[Test.testId%5]);
System.out.print(" Col: ");
System.out.println(Test.COL[Test.testId/5%5]);
int exitValue = myMatrix[ Test.ROW[Test.testId%5] ][ Test.COL[Test.testId/5%5] ];
System.out.println("The exit value is: " + exitValue);
System.exit( exitValue );
} //end of main
Files for example 2
Input to replacer
javatest_single.rep (replacer
Specfile)
javatest_single.javatmp
(java template file)
javatest.mtp (Makefile template)
Output
t.java
javatest.reg
javatest.mk
javatest.rpt