NSS API Guidelines
Newsgroup: mozilla.dev.tech.cryptoIntroduction
This document describes how the NSS code is organized, the libraries that get built out of the NSS sources, and some guidelines for writing NSS code. The guidelines will familiarize you with some of the ways that things are done in the NSS code. This will help you to understand the existing NSS code. It should also help you figure out how to write new code and where to put it. Some of the guidelines in this document are more forward-looking than documentary: these rules are to help us achieve more consistent and usable code in the future, but some of the existing code doesn't follow all of these rules. This document contains the following sections:- NSS API Structure
- Naming Conventions
- Opaque Data Structures
- Memory Allocation with Arenas
- Error Handling
- Thread Safety
- Methods/Functions Design
NSS API Structure
-
This section explains the structure and relationships of the
NSS libraries. The Layering section
explains how the NSS code is layered and how higher-level
functions wrap low-level functions. The
Libraries section descibes the NSS libraries, the functionality
each provides, and the layer in which the library (mostly)
operates.
Layering
Each separate component of the API should live in its own layer. The functions in these APIs should never call API layers above them. In addition, some low-level APIs may be completely opaque to higher level layers. That is, access to these functions should only be provided by the API directly above them. The NSS APIs are layered as shown in the diagram: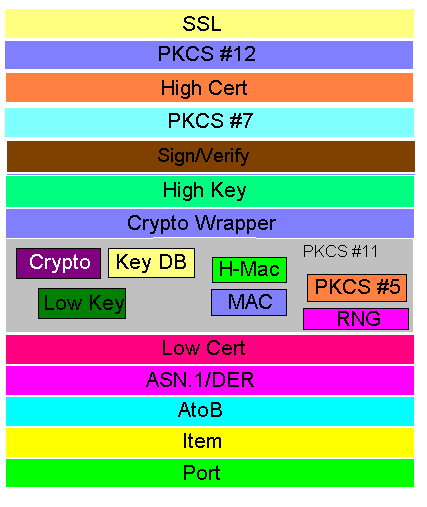
Libraries
NSS compiles into the libraries described below. The Layer indicates the main layer (as in the diagram above) in which the library operates. The Directory is the location of the library code in the NSS source tree. The Public Headers is a list of header files that contain types and functions that are publicly available to higer-level APIs.| Library | Description | Layer | Directory | Public Headers |
|---|---|---|---|---|
| certdb | Provides all certificate handling functions and types. The certdb library manipulates the certificate database (add, create, delete certificates and CRLs). It also provides general certificate-handling routines (create a certificate, verify, add/check certificate extensions). | Low Cert | lib/certdb | cdbhdl.h, certdb.h, cert.h, certt.h |
| certhi | Provides high-level certificate-related functions that do not access the certificate database nor individual certificate data directly. Currently OCSP checking settings are exported through certhi | High Cert | lib/certhigh | ocsp.h, ocspt.h |
| crmf | Provides functions and data types to handle Certificate Management Message Format (CMMF) and Certificate Request Message Format (CRMF, see RFC 2511) data. CMMF no longer exists as a proposed standard; CMMF functions have been incorporated into the proposal for Certificate Management Protocols (CMP). | Same Level as SSL | lib/crmf | cmmf.h, crmf.h, crmft.h, cmmft.h, crmffut.h |
| cryptohi | Provides high-level cryptographic support operations --such as signing, verifying signatures, key generation and manipulation, and hashing-- and data types. This code is above the PKCS #11 layer. | Sign/Verify | lib/cryptohi | cryptohi.h, cryptoht.h, hasht.h, keyhi.h, keythi.h, key.h, keyt.h, sechash.h |
| fort | Provides a PKCS #11 interface to Fortezza crypto services. Fortezza is a set of security algorithms used by the U.S. government. There is also a swft library that provides a software-only implementation of a PKCS #11 Fortezza token. | PKCS #11 | lib/fortcrypt | cryptint.h, fmutex.h, fortsock.h, fpkcs11.h, fpkcs11f.h, fpkcs11t.h, fpkmem.h, fpkstrs.h, genci.h, maci.h |
| freebl | Provides the API to actual cryptographic operations. The freebl is a wrapper API: you must supply a library that implements the cryptographic operations (such as BSAFE from RSA Security). (This is also known as the "bottom layer" API, or BLAPI.) | Within PKCS #11, wraps Crypto | lib/freebl | blapi.h, blapit.h |
| jar | Provides support for reading a writing data in Java Archive (jar) format, including zlib compression. | Port | lib/jar | jar-ds.h, jar.h, jarfile.h |
| nss | Provides high-level initialiazation and shutdown of security services. Specifically, this library provides NSS_Init() for establishing default certificate, key, and module databases and initializing a default random number generator. NSS_Shutdown() closes the databases to prevent further access by an application. | Above High Cert, High Key | lib/nss | nss.h |
| pk11wrap | Provides access to PKCS #11 modules through a unified interface. The pkcs11wrap library provides functions for selecting/finding PKCS #11 modules and slots. It also provides functions that invoke operations in selected modules and slots (key selection and generation, signing, encryption and decryption, etc.). | Crypto Wrapper | lib/pk11wrap | pk11func.h, secmod.h, secmodt.h |
| pkcs12 | Provides functions and types for encoding and decoding PKCS #12 data. PKCS #12 can be used to to encode keys and certificates for export or import into other applications. | PKCS #12 | lib/pkcs12 | pkcs12t.h, pkcs12.h, p12plcy.h, p12.h, p12t.h |
| pkcs7 | Provides functions and types for encoding and decoding encrypted data in PKCS #7 format. PKCS #7 is used, for example, to encrypt certificate data for exchange between applications or to encrypt S/MIME message data. | PKCS #7 | lib/pkcs7 | secmime.h, secpkcs7.h, pkcs7t.h |
| softoken | Provides a software implementation of a PKCS #11 module. | PKCS #11: implementation | lib/softoken | keydbt.h, keylow.h, keytboth.h, keytlow.h, secpkcs5.h, pkcs11.h, pkcs11f.h, pkcs11p.h, pkcs11t.h, pkcs11u.h |
| ssl | Provides an implementation of the SSL protocol using NSS and NSPR. | SSL | lib/ssl | ssl.h, sslerr.h, sslproto.h, preenc.h |
| secutil | Provides utility functions and data types used by other libraries. The library supports base-64 encoding/decoding, reader-writer locks, the SECItem data type, DER encoding/decoding, error types and numbers, OID handling, and secure random number generation. | Utility for any Layer | lib/util | base64.h, ciferfam.h, nssb64.h, nssb64t.h, nsslocks.h, nssrwlk.h, nssrwlkt.h, portreg.h, pqgutil.h, secasn1.h, secasn1t.h, seccomon.h, secder.h, secdert.h, secdig.h, secdigt.h, secitem.h, secoid.h, secoidt.h, secport.h, secrng.h, secrngt.h, secerr.h, watcomfx.h |
Naming Conventions
-
This section describes the rules that (ideally) should be followed
for naming and identifying new files, functions, and data types.
CVS ID
Each file should include a CVS ID string for identification. The preferred format is
"@(#) $RCSfile: nss-guidelines.html,
v $ $Revision: 1.6 $ $Date: 2006/09/16 01:07:48 $ $Name: MOZILLA-ORG_2008_04_21_00_ARCHIVE $"
You can put the string in a comment or in a static char array (use
#idfef DEBUG to include the array in debug builds only). The
advantage of using an array is that you can use strings(1) to
pull the ID tags out of a (debug) compiled library. You can even put them
in header files; the header files are protected from double inclusion.
The only catch is that you have to disambiguate the name of the array.
Here is an example from lib/base/baset.h:
#ifdef DEBUG
static const char BASET_CVS_ID[] = "@(#) $RCSfile: nss-guidelines.html,
v $ $Revision: 1.6 $ $Date: 2006/09/16 01:07:48 $ $Name: MOZILLA-ORG_2008_04_21_00_ARCHIVE $";
#endif /* DEBUG */
The difference between this and Id is that Id has some useless information
(every file is "experimental"), and doesn't have Name. Name is the
tag (if any) from which this file was pulled. If you're good about tagging
your releases and then checking out (or exporting!) from the tag to do your
build, this saves you from having to screw around with specific files
revision numbers.
Header Files
We have a standard ideal naming system for include files. We'd been moving towards one, but for the NSS 3.0 project we actually wrote it down.| Data Types | Function Prototypes | |
|---|---|---|
| Public | nss____t.h | nss____.h |
| Friend (only if required) | nss____tf.h | nss____f.h |
| NSS-private | ____t.h | ____.h |
| Module-private | ____tm.h | ____m.h |
The files on the right include the files to their left; the files in a row include the files directly above them. Header files always include what they need; the files are protected against double inclusion (and even double opening by the compiler). Note that not all eight files necessarily exist. Further, this is the simple ideal; often reality is more complex.
It'd be nice to keep names to 8.3, even though we no longer support win16. This usually gives us four characters to identify a module of NSS.
In short:
- Header files for consumption outside NSS start with "nss."
- Header files with types have a trailing "t"; header files with prototypes don't. "extern" declarations of data also go in the prototypes files.
- "Friend" headers are for things that we really wish weren't used by non-NSS code, but which are. Those files have a trailing "f," and their use should be deprecated.
- "Module" heaaders are for things used only within a specific subset of NSS; things which would have been "static" if we had combined separate C source files together. These header files have a trailing "m."
Functions and Types
There are a number of ways of doing things in our API, as well as naming decisions for functions that can affect the usefulness of our library. If our library is self-consistent with how we accomplish these tasks, it makes it easier for the developer to learn how to use our functions. This section of the document should grow as we develop our API. First some general rules (these rules derive from the existing coding practice inside the security library, since consistency is more important then religious wars about "what looks pretty").- Public functions should have the form LAYER_Body() where LAYER is an all caps prefix for what layer the function lives in, and Body is concatenated English words where the beginning letter of each word is capitalized ("camel-capped"). For Example: LAYER_CapitalizedEnglishWords() or CERT_DestroyCertificate().
- Data types and typdefs should have the Form LAYERBody, with the same definitions for LAYER as public functions and Body is camel-capped English words. For example: LAYERCapitalizedEnglishWords or SECKEYPrivateKey.
- Structures should have the same name as their typedefs with the string Str added to the end. For example LAYERCapitalizedEnglishWordsStr or SECKEYPrivateKeyStr.
- Private functions should have the form layer_Body() where layer is the all lower case prefix for what layer the function lives in, and Body is camel-capped English words. Private functions include functions that may be "public" in a C sense, but are not exported out of the layer. For example: layer_CapitalizedEnglishWords() or pk11_GenerateKeyID().
- Public macros should have the form LAYER_BODY() where LAYER is an all caps prefix for what layer the macro lives in, and BODY is camel-capped English words separated by underscores. For example: LAYER_UPPER_CASE_ENGLISH_WORDS() or DER_CONVERT_BIT_STRING().
- Structure members for exposed data structures should have the form capitalizedEnglishWords (the first letter uncapitalized). For example: PK11RSAGenParamsStr.keySizeInBits
-
For members of enums, our current API has no standard (typedefs for
enums should follow the Data types standard). There seem to be three
reasonable options:
- Enum members have the same standard as exposed data structure members.
- Enum members have the same standard as Data types.
- Enum members have the same standard as Public Macros (minus the '()' of course).
- Callback functions and functions used in function tables should have a typedef used to define the complete signature of the given function. Function typedefs should have the following format: LAYERBody() with the same definitions for LAYER as public functinos and Body is camel-capped English words. For example: LAYERCapitalizedEnglishWords or SECKEYPrivateKey.
Opaque Data Structures
-
There are many data structures in the security library whose definition
is effectively private to the portion of the security library that defines
and operates on those data structures. External code does not have access
to these definitions. The goal here is to increase the opaqueness of these
structures. This will allow us to modify the size, definition, and format
of these data structures in future releases without interfering with the
operation of existing applications that use the security library.
The first task is to make sure the declaration of the data structure
lives in a private header file, while the definition lives in the public.
Since the current standard in the security library is to typedef
the data structure name, the easiest way to accomplish this would be to
add the typedef to the public header file.
For example, for the structure SECMyOpaqueData you would add:
typedef struct SECMyOpaqueDataStr SECMyOpaqueData;
Then add the actual structure definition to the private header file.
In this same example:
struct SECMyOpaqueDataStr {
unsigned long myPrivateData1;
unsigned long myPrivateData2;
char *myName;
};
The second task is to determine if individual data fields within the
data structure is part of the API. One example may be the
peerCert field in an SSL data structure. Accessor functions
for these data elements should be added to the API.
There can be legitimate exceptions to this "make everything opaque"
rule, like container structures such as SECItem, or maybe
linked list data structures. These data structures need to be examined
on a case by case basis to determine if 1) they are truly stable and
will not change in future release, and 2) it is necessary for the callers
of the API to know the size of these structures (as they may allocate
new ones and pass them down).
Memory Allocation with Arenas
-
This section discusses memory allocation using arenas. Current NSS code
uses arenas, and this section explains some of the improvements that
we will be making to improve the facility in the future.
NSS does make some use of traditional memory allocation functions, wrapping
NSPR's PR_Alloc in a util function called PORT_Alloc.
But NSS will make widespread use of an NSPR memory-allocation facility that
uses "Arenas" and "ArenaPools." It was added for use by javascript; it is
a fast, lightweight, non-thread-safe (though "free-threaded")
implementation.
Experience has shown that users of the security library expect
the arenas to be threadsafe, so we found that we had to add locking.
While we are at it, we want to add a couple of other changes we found
useful.
- There has always been confusion as to what the difference is between Arenas and ArenaPools, and assertions that usually the terms are being used incorrectly. So, we will simplify it down to one type for the logical "memory bucket" type. Consensus called that type NSSArena.
- We have lots of code that takes an optional arena pointer, and which will use the arena if there is one, or the heap if there isn't. Therefore, we'll wrap that logic into the allocators. Sure, knowing what to free takes some discipline not to leak, but it simplifies things a lot. Also, the implementation of free ``works'' (i.e., doesn't crash) no matter if it came from an arena or the heap, as long as it was allocated from our allocators. Combined with purify, this also helps us catch cases where things being allocated by one allocator are freed by another, which is a common Windows pitfall.
- The security code often wants to be sure to zero memory when it's being freed; we'll just add it to the primitives to be done with it.
- Thread A marks the arena, and allocates some memory from it.
- Thread B allocates some memory from the arena.
- Thread A releases the arena back to the mark.
- (Thread B now finds itself with a pointer to released data.)
- Some thread -- doesn't matter which -- allocates some data from the arena; this may well overlap the chunk thread B has.
- Boom.
- Arenas, and the way they let you allocate a whole bunch of stuff and then blow them all away at once,
- Lazy creation of pure-memory objects from ASN.1 blobs, so the mere use of (e.g.) NSSPKIXCertificate doesn't drag in all the code for all the constituent objects unless they're actually used, and
- Our agressive pointer-tracking facility.
Error Handling
-
NSS 3.0 introduces the concept of an "error stack." When something goes
wrong and the call stack unwinds with routines returning an error
indication, each level (at least, each level that has something to say
about the problem) layers its own error number on the stack. At the
bottom of the stack is the fundamental error (e.g. "file not found")
and at the top is an error relating to what you were trying to do.
Note that error stacks are vertical, never horizontal: if multiple
things go wrong simultaneously, and you want to report them all, you need
another mechanism.
Errors, though integers, are done as external constants instead of
preprocessor definitions. This is so that adding one error doesn't
trigger the entire tree to rebuild. Likewise, the external references
to errors are made in the prototypes files, with the functions that
can return them.
Error stacks are thread-private.
The usual semantic is that public routines clear the stack first, private
routines don't. Usually, every public routine has a private counterpart,
and the implementation of the public routine looks like this:
NSSImplement rv *
NSSType_Method
(
NSSType *t,
NSSFoo *arg1,
NSSBar *arg2
)
{
nss_ClearErrorStack();
#ifdef DEBUG
if( !nssFoo_verifyPointer(arg1) ) return (rv *)NULL;
if( !nssBar_verifyPointer(arg2) ) return (rv *)NULL;
#endif /* DEBUG */
return nssType_Method(t, arg1, arg2);
}
Besides error cases, all documented entry points should check pointers,
wherever possible, in the debug case. Pointers to user-supplied buffers
and templates should be checked against NULL. Pointers to context-style
functions should be checked using special debug macros. These macros only
define code when DEBUG is turned on, and provide a way for systems to
register, deregister, and check valid pointers.
SECPORT_DECL_PTR_CLASS(classname,size) - declare
a class of pointers (labelled classname) this object file needs
to check. This class is local only to this object file. Size is
the expected number of pointers of type classname.
SECPORT_DECL_GLOBAL_PTR_CLASS(classname,size) -
same as above except classname is can be used in other object files.
SECPORT_ADD_POINTER(classname,pointer) - Add
pointer as a valid pointer for class classname. This is
usually called by a Create function.
SECPORT_VERIFY_POINTER(classname,pointer,secError,
returnValue)- Check if a given pointer really belongs
to the requested class. If it doesn't set the error secError and
return the value returnValue.
SECPORT_REMOVE_POINTER(classname,pointer) - Remove
a pointer from the valid list. Usually called by a Destroy function.
Finally, error logging should be added an documented when debug is turned
on. Interfaces for these are in NSPR.
Thread Safety
-
Code developed using the NSS APIs needs to be make use of the thread
safety features. The first part to examine is object creation and
deletion. Object creation is usually not a problem. No other
threads have access to memory just allocated in creation. (Exceptions to
this include objects which are created on the fly or as global objects.)
Deletion, on the other hand, may be trickier. Other threads may be
referencing the object at the time a different thread chooses to delete it.
Some of these semantics depend on the way the application is using the
object, and how and when the application chooses to destroy it. For
some data structures, this problem can be removed by protected reference
counting. The object does not ever disappear until all users of the object
have released it.
- This semantic is documented in the functions that use these data structures.
- These data structures are used for single streams, and not meant to be reused.
Next examine any global data. These include function local static structures. Global data that just gets initialized, but never changed, does not need to be protected by mutexes. We should also determine if global data should be moved to a session context (see session context and global effects below). Also note that permanent objects (like data in files, databases, tokens, etc.) should be treated as global data. Global data which is only changed rarely, should be protected by reader/writer locks.
Besides global data, allocated data that gets modified needs to be examined. Data that's just allocated within a function is safe to modify, no other code has access to that data pointer. Once that data pointer is made visible to the 'outside' (either by returning the pointer, or attaching the pointer to an existing visible data structure) access to the data should be protected. Data structures that are basically "read-only" (like SECKEYPublicKeys, or PK11SymKeys) need not be protected.
Many of the data structures in the security code contain some sort of session state or session context. These data structures may be accessed without data protection as long asA major type of global and allocated data that should be examined is various data on lists. Queued, linked, and hash table stored objects should be examined with special care. Make sure adding, removing, accessing, and destroying these objects are all safe operations.
There are a number of strategies, and full books about how to safely access data on lists. Here are a couple of the simple strategies and their issues:
-
Use hash tables: Hash table lookups are usually quite
fast, limiting the contention on the lock. This is best for large
lists of objects. Be sure to calculate the hash value first, then
only lock over the hash table value itself. Be sure to increment the
reference count on the returned objected before unlocking. Examples
of hash tables can be found in
security/nss/lib/certdb/pcertdb.c
Lock over the entire search: For small linked listed, queues,
or arrays, you can lock over the entire search. This strategy is best
if the lists are short, and even better, if the lists are relatively
read only (they don't change very often) and reader/writer locks
are used.
Copy the linked list: Instead of operating on the global list,
you can copy the list. This also requires small lists.
Lock over single element with retry: For medium sized lists,
you can secure a reference to each element, complete your
complicated test, then detect of the given element has been removed
from the list. In the case of removal, the search can either be 1)
restarted, or 2) terminated. This method is a lot more complicated
than the other methodes, and requires the calling search code to be
tolerant of looking at the same element multiple times (potenitally).
Examples of the last three strategies can be found in
security/nss/lib/pk11wrap/pk11slot.c.
In order to be fully thread safe, your code must understand the semantics of the service functions it calls, and whether they are thread safe. For now we should document (internal) what service functions we call, and how we expect them to behave in a threaded environment.
Finally, from an API point of view, we should examine functions which have global effects. Functions like XXX_SetDefaultYYY(); should not operate on global data, particularly if they may be called multiple times to provide different semantics for different operations. For example, operations like
-
SEC_SetKey(keyForOperation);
SEC_Encrypt(Data,Length);
The exception to this global effects rule may be functions which set global state for an application at initialization time.
Methods/Functions Design
Init, Shutdown Functions
If a layer has some global initialization tasks that need to be completed before the layer can be used, that layer should supply an initialization function of the form LAYER_Init(). If an initialization function is supplied, a corresponding LAYER_Shutdown() function should also be supplied. LAYER_INIT() should increment a count of the number of times it is called, and LAYER_Shutdown() should decrement that count, and shutdown when the count reaches '0'.Open, Close Functions
Open functions should have a corresponding close function. Open and close function are not reference counted like init and shutdown functions.Creation Functions
In general, data objects should all have functions which create them. These functions should have the form LAYER_CreateDataType[FromDataType](). For instance generating a new key would change from PK11_KeyGen() to PK11_CreateSymKey().Destruction Functions
In the security library we have 3 different ways of saying "get rid of this data object": Free, Delete, and Destroy. It turns out there are several different semantics of getting rid of a data object as well: 1) decrement the reference count, and when the object goes to '0' free/delete/destroy it, 2) destroy it right now, this very instance, not matter what, 3) make any permanent objects associated with this data object go away, a combination of 1 and 3 or 2 and 3. Unfortunately within the security library Free, Delete, and Destroy are all used interchangeably for all sorts of object destruction: For instance CERT_DestroyCertificate() is type 1, PK11_DestroySlot() is type 2, and PK11_DestroyTokenObject() is type 3 [NOTE: for non-reference counted functions 1 and 2 are the same]. We are standardizing on the following definitions:Destroy - means #1 for reference counted objects, #2 for non reference counted objects.
Delete - means #3.
This has the advantage of not surfacing the reference countedness of a data object. If you own a pointer to an object, you just always destroy it. There is no way to destroy an object bypassing it's reference count. Also, the signature of public destruction functions do not have the 'freeit' PRBool, since the structures that are being freed are opaque.
Dup, Copy, and Reference Functions
Functions that return a new reference or copy of a given object should have the form LAYER_DupDataType(). For instance CERT_DupCertifiate() will remain the same, but PK11_ReferenceSlot() will become PK11_DupSlot(), and PK11_CloneContext() will become PK11_DupContext().Search Functions
There are several different kinds of searches done in the security library. The first is a search for exactly one object that meets the given criteria. These types of searches include CERT_FindCertByDERCert(), PK11_FindAnyCertFromDERCert(), PK11_FindKeyByCert(), PK11_GetBestSlot(). These functions should all have the form LAYER_FindDataType[ByDataType]().The second kind of search looks for all the objects that match a given criteria. These functions operate on a variety of level. Some return allocated arrays of data, some return linked lists of data, others use callbacks to return data elements one at a time. Unfortunately there are good reasons to maintain all of these types. So here are the guidelines to make them more manageable:
All callback operating search functions should be in the low level of the API (if exposed at all). Application writers dealing with SSL and PKCS #7 layers should not have to see any of these functions. These functions should have the form LAYER_TraverseStorageObjectOrList().
List and Array returning functions should be available at the higher layers of the API, most wrapping LAYER_Traverse() functions. They should have the form LAYER_LookupDataType{List|Array}[ByDataType]().
Accesssor Functions
Accessor Functions should use the following formats:-
LAYER_DataTypeGetElement() -- Get a specific element of a
data structure.
LAYER_DataTypeSetElement() -- Set a specific element of a
data structure.
LAYER_DataTypeExtractDataType() -- Get a pointer to the
second data type which was derived for elements of the first data
type.
Parameter ordering
Most functions will have a 'Natural' ordering for parameters. To keep consistency we should have some some minimal parameter consistency. First, for most functions, they can be seen as operating on a particular object. That object the function is operating on should come first. For instance most SSL functions this is usually the NSPR Socket, or the SSL Socket structure; Update, final, encrypt, decrypt type functions operate on their state contexts; etc.All encrypt/decrypt functions which return data inline should have a consistent signature of:
SECStatus MY_FunctionName(MyContext *context,
unsigned char *outBuf,
SECBufferLen *outLen,
SECBufferLen maxOutLength,
unsigned char *inBuf,
SECBufferLen inLen)
Encrypt/decrypt like functions that have different properties (additional
parameters, callbacks, etc.) should insert the additional parameters
between the context (first parameter) and the output buffer.
All hashing update, MACing update, and encrypt/decrypt functions which act like filters should have a consistent signature of :
SECStatus PK11_DigestOp(PK11Context *context,
unsigned char *inBuf,
SECBufferLen inLen)
Functions like these that have different properties (additional parameters,
callbacks, etc.) should insert the additional parameters between the context
(first parameter) and the input buffer.
Within your layer, multiple similar functions should have consistent
parameter order.
Callback Functions
Callback functions should all contain an opaque parameter (void *) as their
first argument, which is passed by the original caller. Callbacks which
are set (like SSL callbacks) should have defaults which provide generally
useful semantics.