You are currently viewing a snapshot of www.mozilla.org taken on April 21, 2008. Most of this content is highly out of date (some pages haven't been updated since the project began in 1998) and exists for historical purposes only. If there are any pages on this archive site that you think should be added back to www.mozilla.org, please file a bug.

nsIURI
This interface provides support for a uniform resource identifier (URI) w/ i18n support. It is scriptable.
URIs are essentially structured names for things -- anything. This interface provides accessors to set and query the most basic components of an URI. Subclasses, including
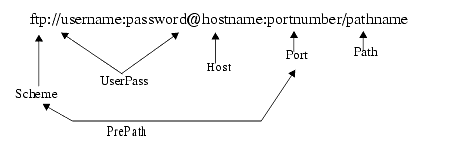
nsIURL, impose greater structure on the URI.This interface follows Tim Berners-Lee's URI spec (RFC2396) [1], where the basic URI components are defined as such:
The definition of the URI components has been extended to allow for internationalized domain names [2] and the more generic IRI structure [3].
[1]http://www.ietf.org/rfc/rfc2396.txt
[2] http://www.ietf.org/internet-drafts/draft-ietf-idn-idna-06.txt
[3] http://www.ietf.org/internet-drafts/draft-masinter-url-i18n-08.txt
AUTF8String attributes may contain unescaped UTF-8 characters. Consumers should be careful to escape the UTF-8 strings as necessary, but should always try to "display" the UTF-8 version as provided by this interface. AUTF8String attributes may also contain escaped characters. Unescaping URI segments is not advised unless there is intimate knowledge of the underlying charset or there is no plan to display (or otherwise enforce a charset on) the resulting URI substring.
Performs a URI equivalence test (not a strict string comparison), eg. http://foo.com:80/ == http://foo.com/ between this URI and another URI.
Syntax:
boolean nsIURI::equals(in nsIURI other)Parameters:
nsresult:
Does scheme checks without requiring the users of
nsIURItoGetScheme, thereby saving extra allocating and freeing.Syntax:
boolean nsIURI::schemeIs(in string scheme)Parameters:
nsresult:
Clones the current URI. For some protocols, this is more than just an optimization. For example, under MacOS, the spec of a file URL does not necessarily uniquely identify a file since two volumes could share the same name.
Syntax:
nsIURI nsIURI::clone()Parameters:
Returns:
This method resolves a relative string into an absolute URI string, using this URI as the base.
Note: some implementations may have no concept of a relative URI.
Syntax:
AUTF8String nsIURI::resolve(in AUTF8String relativePath)Parameters:
Returns:
Gets and sets a string representation of the URI. Setting the spec causes the new spec to be parsed, initializing the URI. Some characters may be escaped.
Gets the prePath (eg. scheme://user:password@host:port), ie, the string before the path. This is useful for authentication or managing sessions. Some characters may be escaped.
Gets and sets the Scheme, which is the protocol to which this URI refers. The scheme is restricted to the US-ASCII charset per RFC2396.
Gets and sets the username:password (or username only if the value doesn't contain a ':'). Some characters may be escaped.
Gets and sets the username or password, assuming the
preHostconsists of username:password. Some characters may be escaped.Gets and sets the host:port (or simply the host, if port == -1). Characters are NOT escaped.
Gets and sets the host, the internet domain name to which this URI refers. It could be an IPv4 (or IPv6) address literal. If supported, it could be a non-ASCII internationalized domain name. Characters are NOT escaped.
Gets and sets the port. A port value of -1 corresponds to the protocol's default port (eg. -1 implies port 80 for http URIs).
Gets and sets the path, typically including at least a leading '/' (but may also be empty, depending on the protocol). Some characters may be escaped.
Gets the URI spec with an ASCII compatible encoding. Host portion follows the IDNA draft spec. Other parts are URL-escaped per the rules of RFC2396. The result is strictly ASCII.
Gets the URI host with an ASCII compatible encoding. Follows the IDNA draft spec for converting internationalized domain names (UTF-8) to ASCII for compatibility with existing internet infrasture.
Gets the charset of the document from which this URI originated. An empty value implies UTF-8. If this value is something other than UTF-8 then the URI components (e.g., spec, prePath, username, etc.) will all be fully URL-escaped. Otherwise, the URI components may contain unescaped multibyte UTF-8 characters.
| Written by:Ellen Evans | Comments, questions, complaints?
Bug 143387 |