You are currently viewing a snapshot of www.mozilla.org taken on April 21, 2008. Most of this content is highly out of date (some pages haven't been updated since the project began in 1998) and exists for historical purposes only. If there are any pages on this archive site that you think should be added back to www.mozilla.org, please file a bug.
Whitespace in the DOM
by L. David Baron <dbaron@dbaron.org>The issue
The presence of whitespace in the DOM can make manipulation of the
content tree difficult in unforseen ways. In Mozilla, all whitespace
in the text content of the original document is represented in the DOM
(this does not include whitespace within tags). (This is needed
internally so that the editor can preserve formatting of documents and
so that white-space: pre in CSS will work.) This means
that:
- there will be some text nodes that contain only whitespace, and
- some text nodes will have whitespace at the beginning or end.
In other words, the DOM tree for the following document will look like the image below (using "\n" to represent newlines):
<!-- My document -->
<html>
<head>
<title>My Document</title>
</head>
<body>
<h1>Header</h1>
<p>
Paragraph
</p>
</body>
</html>
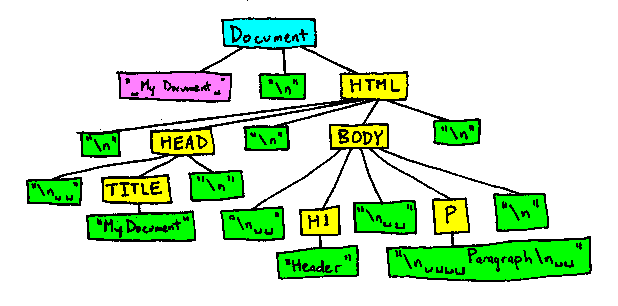
This can make things a bit harder for any users of the DOM who want to iterate through content, excluding the whitespace.
Making things easier
The Javascript file nodomws.js defines several functions that make it easier to deal with whitespace in the DOM:
/**
* Throughout, whitespace is defined as one of the characters
* "\t" TAB \u0009
* "\n" LF \u000A
* "\r" CR \u000D
* " " SPC \u0020
*
* This does not use Javascript's "\s" because that includes non-breaking
* spaces (and also some other characters).
*/
/**
* Determine whether a node's text content is entirely whitespace.
*
* @param nod A node implementing the |CharacterData| interface (i.e.,
* a |Text|, |Comment|, or |CDATASection| node
* @return True if all of the text content of |nod| is whitespace,
* otherwise false.
*/
function is_all_ws( nod )
{
// Use ECMA-262 Edition 3 String and RegExp features
return !(/[^\t\n\r ]/.test(nod.data));
}
/**
* Determine if a node should be ignored by the iterator functions.
*
* @param nod An object implementing the DOM1 |Node| interface.
* @return true if the node is:
* 1) A |Text| node that is all whitespace
* 2) A |Comment| node
* and otherwise false.
*/
function is_ignorable( nod )
{
return ( nod.nodeType == 8) || // A comment node
( (nod.nodeType == 3) && is_all_ws(nod) ); // a text node, all ws
}
/**
* Version of |previousSibling| that skips nodes that are entirely
* whitespace or comments. (Normally |previousSibling| is a property
* of all DOM nodes that gives the sibling node, the node that is
* a child of the same parent, that occurs immediately before the
* reference node.)
*
* @param sib The reference node.
* @return Either:
* 1) The closest previous sibling to |sib| that is not
* ignorable according to |is_ignorable|, or
* 2) null if no such node exists.
*/
function node_before( sib )
{
while ((sib = sib.previousSibling)) {
if (!is_ignorable(sib)) return sib;
}
return null;
}
/**
* Version of |nextSibling| that skips nodes that are entirely
* whitespace or comments.
*
* @param sib The reference node.
* @return Either:
* 1) The closest next sibling to |sib| that is not
* ignorable according to |is_ignorable|, or
* 2) null if no such node exists.
*/
function node_after( sib )
{
while ((sib = sib.nextSibling)) {
if (!is_ignorable(sib)) return sib;
}
return null;
}
/**
* Version of |lastChild| that skips nodes that are entirely
* whitespace or comments. (Normally |lastChild| is a property
* of all DOM nodes that gives the last of the nodes contained
* directly in the reference node.)
*
* @param sib The reference node.
* @return Either:
* 1) The last child of |sib| that is not
* ignorable according to |is_ignorable|, or
* 2) null if no such node exists.
*/
function last_child( par )
{
var res=par.lastChild;
while (res) {
if (!is_ignorable(res)) return res;
res = res.previousSibling;
}
return null;
}
/**
* Version of |firstChild| that skips nodes that are entirely
* whitespace and comments.
*
* @param sib The reference node.
* @return Either:
* 1) The first child of |sib| that is not
* ignorable according to |is_ignorable|, or
* 2) null if no such node exists.
*/
function first_child( par )
{
var res=par.firstChild;
while (res) {
if (!is_ignorable(res)) return res;
res = res.nextSibling;
}
return null;
}
/**
* Version of |data| that doesn't include whitespace at the beginning
* and end and normalizes all whitespace to a single space. (Normally
* |data| is a property of text nodes that gives the text of the node.)
*
* @param txt The text node whose data should be returned
* @return A string giving the contents of the text node with
* whitespace collapsed.
*/
function data_of( txt )
{
var data = txt.data;
// Use ECMA-262 Edition 3 String and RegExp features
data = data.replace(/[\t\n\r ]+/g, " ");
if (data.charAt(0) == " ")
data = data.substring(1, data.length);
if (data.charAt(data.length - 1) == " ")
data = data.substring(0, data.length - 1);
return data;
}
Example
The following code demonstrates the use of the functions above.
It iterates over the children of an element (whose children are
all elements) to find the one whose text is "This is the third
paragraph", and then changes the class attribute and the contents
of that paragraph. (See a demonstration of
this code.)
var cur = first_child(document.getElementById("test"));
while (cur)
{
if (data_of(cur.firstChild) == "This is the third paragraph.")
{
cur.className = "magic";
cur.firstChild.data = "This is the magic paragraph.";
}
cur = node_after(cur);
}